
 红包分享
红包分享 钱包管理
钱包管理


 0
0- 0
- 1
半导体行业观察
Groq 是一家人工智能硬件初创公司,最近因其令人印象深刻的演示而广受关注,该演示在其推理 API 上展示了领先的开源模型。它们的吞吐量高达其他推理服务的 4 倍,而收费却低于 Mistral 本身的 1/3。
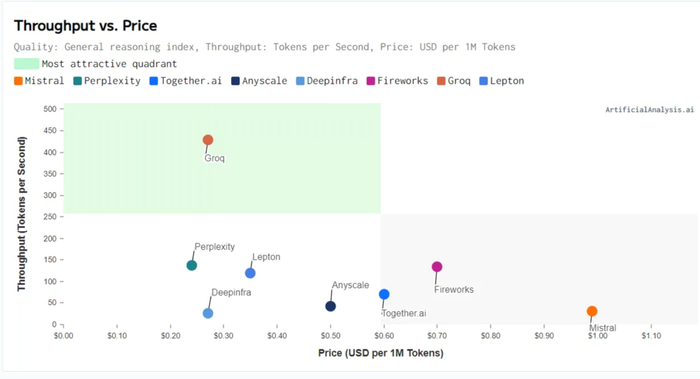
Groq 对于单个序列具有真正令人惊叹的性能优势。这可以使思想链(chain of thought)等技术在现实世界中更加有用。此外,随着人工智能系统变得自治,大模型的输出速度对于代理等应用程序来说需要更高。同样,codegen 也需要显着降低令牌输出延迟。实时 Sora 风格模型可能是一种令人难以置信的娱乐途径。但是,如果延迟太高,这些服务甚至可能对终端市场客户来说不可行或不可用。
这引发了人们对 Groq 硬件和推理服务对人工智能行业革命性的广泛宣传。虽然它确实改变了某些市场和应用的游戏规则,但速度只是其中的一部分,供应链多元化是 Groq 青睐的另一项举措。他们的芯片完全在美国制造和封装。Nvidia、Google、AMD 和其他 AI 芯片需要来自韩国的内存,以及来自台湾的芯片/先进封装。
这些对于 Groq 来说是积极的,但评估硬件是否具有革命性的主要公式是性能/总拥有成本。谷歌对此深有体会。
人工智能时代的曙光已经到来,了解人工智能驱动软件的成本结构与传统软件有很大不同是至关重要的。芯片微架构和系统架构在这些创新型新软件形式的开发和可扩展性中发挥着至关重要的作用。与开发人员成本相对较高的前几代软件相比,运行人工智能软件的硬件基础设施对资本支出和运营支出以及随后的毛利率的影响明显更大。因此,更加重要的是投入大量精力来优化人工智能基础设施,以便能够部署人工智能软件。在基础设施方面具有优势的公司也将在利用人工智能部署和扩展应用程序的能力方面具有优势。
谷歌的基础设施优势是为什么 Gemini 1.5 为谷歌提供服务比 OpenAI GPT-4 Turbo 便宜得多,同时在许多任务中表现更好,尤其是长序列代码。谷歌在单个推理系统中使用了更多的芯片,但他们以更好的性能/总体拥有成本(TCO)做到了这一点。
在这种情况下的性能不仅仅是单个用户每秒的原始tokens,即延迟优化。在评估 TCO 时,必须考虑硬件上同时提供服务的用户数量。这就是为什么改进 LLM 推理的边缘硬件的权衡非常脆弱或没有吸引力的主要原因。大多数边缘系统无法弥补正确运行LLM所需的增加的硬件成本,因为此类边缘系统无法在大量用户之间摊销。至于以极高的批量大小、吞吐量和成本优化来为许多用户提供服务,GPU 是王道。
正如我们在以往所说,许多公司在 Mixtral API 推理服务上确实亏损了。有些还设有非常低的利率限制以限制他们的损失金额。
在这里。我们给Grpq的芯片算一笔账。

对于其他提供 Mixtral API 的人来说,情况并非如此。他们要么在量化方面撒谎,要么点燃风险投资资金来获取客户群。Groq 采取了大胆的举措,在定价上与这些人保持一致,每百万token的定价极低,仅为 0.27 美元。
他们的定价是否像 Together 和 Fireworks 一样基于性能/TCO 计算?还是为了炒作而提供补贴?请注意,Groq 的最后一轮融资是在 2021 年,去年获得了 5000 万美元的 SAFE,目前他们正在筹集资金。
让我们来了解一下 Groq 的芯片、系统、成本分析以及它们如何实现这种性能。

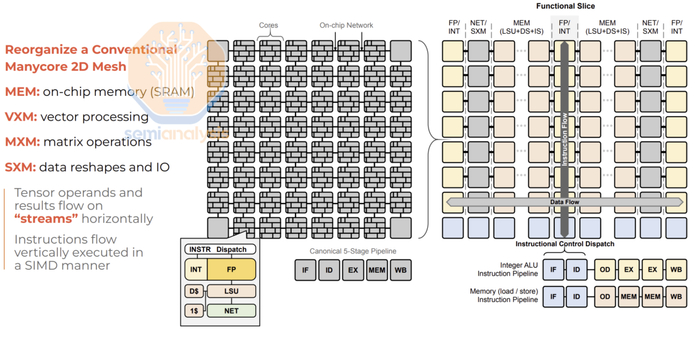

Groq 的芯片具有完全确定性的 VLIW 架构,没有缓冲区,在 Global Foundries 14nm 工艺节点上制造,芯片尺寸达到约 725mm2 。它没有外部存储器,并且在处理过程中将权重、KVCache 和激活等全部保存在片上。由于每个芯片只有 230MB SRAM,因此任何有用的模型实际上都无法安装在单个芯片上。相反,他们必须利用许多芯片来拟合模型并将它们联网。
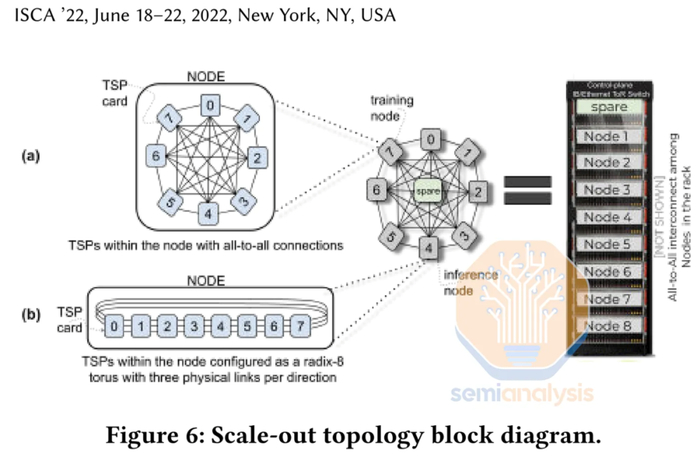
在 Mixtral 模型中,Groq 必须连接 8 个机架,每个机架有 9 台服务器,每台服务器有 8 个芯片。总共需要 576 个芯片来构建推理单元并为 Mixtral 模型提供服务。与 Nvidia 相比,Nvidia 的单个 H100 可以适应低批量大小的模型,并且两个芯片有足够的内存来支持大批量大小。
用于制造 Groq 芯片的晶圆成本可能低于每片 6,000 美元。将此与 Nvidia 的 H100 进行比较,该 H100 芯片尺寸为 814mm2,采用台积电 5nm 的定制变体(称为 4N)。这些晶圆的成本接近每片 16,000 美元。另一方面,与具有极高参数良率的 Nvidia 相比,Groq 的架构在实现良率收获方面似乎不太可行,因为它们禁用了大多数 H100 SKU 约 15% 的芯片。
此外,Nvidia 以每个 H100 芯片约 1,150 美元的价格从 SK Hynix 购买 80GB HBM。Nvidia 还必须为台积电的 CoWoS 付费,并承受良率下降的影响,而 Groq 没有任何片外存储器。Groq 芯片的原材料清单要低得多。Groq 也是一家初创公司,因此他们的芯片产量较低/相对固定成本较高,这包括必须向 Marvell 的定制 ASIC 服务支付高额利润。
下表列出了三种部署,一种是针对 Groq 的,其当前的pipeline并行性和3的batch size,我们听说他们将在下周在生产中实施,其他则概述了延迟优化的 H100 推理部署以及推测解码作为吞吐量优化的 H100 推理部署。

上表极大地简化了经济学(同时忽略了我们稍后将深入讨论的大量系统级成本,并且还忽略了 Nvidia 的巨额利润)。这里的要点是要表明,与延迟优化的 Nvidia 系统相比,Groq 在每代输出的硅材料成本方面具有芯片架构优势。
8xA100 可以为 Mixtral 提供服务,并实现每用户每秒约 220 个token的吞吐量,而 8xH100 可以达到每用户每秒约 280 个token的吞吐量,而无需推测解码(peculative decoding)。通过推测解码,8xH100 推理单元可以实现每用户每秒接近 420 个token的吞吐量。吞吐量可能会超过这个数字,但在 MoE 模型上实现推测解码具有挑战性。
目前还不存在延迟优化的 API 服务,因为经济性非常糟糕。API 提供商目前没有看到为降低延迟而收取 10 倍以上费用的市场。一旦代理和其他极低延迟任务变得更加流行,基于 GPU 的 API 提供商可能会在其当前吞吐量优化的 API 的同时推出延迟优化的 API。
一旦 Groq 下周实施其批处理系统,带有推测性解码的延迟优化 Nvidia 系统在吞吐量和成本上仍然远远落后于没有推测解码的 Groq。此外,Groq 使用的是更古老的 14 纳米工艺技术,并向 Marvell 支付了相当大的芯片利润。如果 Groq 获得更多资金并能够在 2025 年下半年提高下一代 4nm 芯片的产量,那么经济状况可能会开始发生重大变化。请注意,Nvidia 远非坐以待毙,因为我们认为他们将 在不到一个月的时间内发布下一代 B100。
在吞吐量优化的系统中,经济性发生显着变化。Nvidia 系统在 BOM 基础上每美元的性能提高了一个数量级,但每个用户的吞吐量较低。对于吞吐量优化场景,Groq 在架构上根本没有竞争力。
然而,对于购买系统和部署系统的人们来说,上面提供的简化分析并不是查看业务案例的正确方法,,因为该分析忽略了系统成本、利润、功耗等。下面,我们提供性能/总拥有成本分析。
一旦我们考虑到这些因素,token经济学(cred swyx 是时髦的新词)看起来就会非常不同。

Nvidia 在其 GPU 基板上获得了巨大的毛利率。此外,服务器的 350,000 美元价格远高于 H100 服务器的超大规模服务器成本,还包括内存、8 个总带宽为 3.2Tbps 的 InfiniBand NIC(此推理应用程序不需要)以及相当大的成本。OEM 利润率高于 Nvidia 利润率。
对于 Groq,我们正在估算系统成本,并考虑有关芯片、封装、网络、CPU、内存的详细信息,同时假设总体 ODM 利润较低。我们也不包括 Groq 因销售硬件而收取的利润,因此虽然看起来像是Apples vs Oranges,但这也是 Groq 的成本与推理 API 提供商的成本的公平比较,因为两者都提供相同的产品/模型。

值得注意的是,8 个 Nvidia GPU 只需要 2 个 CPU,但 Groq 的 576 芯片系统目前拥有 144 个 CPU 和 144TB RAM。

